
Best Practices¶
This topic provides best practices to follow while designing REST APIs. It provides guidance for common challenges when implementing REST APIs.
REST API Maturity¶
This section provides best practices for designing REST APIs based on the Richardson Maturity Model.
The Richardson Maturity Model is a model (developed by Leonard Richardson) that breaks down the principal elements of a REST approach into three steps. This model introduces resources, HTTP verbs, and hypermedia controls. See Richardson Maturity Model for more information (written by Martin Fowler).

APIs SHOULD use level 3, making use of links for hypermedia controls. This is a very efficient way for expressing relationships to other REST resources.
Here is an example of a response for GET request.
GET https://xcelerator.siemens.cloud/devices/36542 HTTP/1.1
Accept: application/json
{
"data": {
"name": "My device",
"deviceType": {
"id": "hvac",
"name": "HVAC device"
},
"links": {
"self": "https://xcelerator.siemens.cloud/devices/36542",
"location": "https://xcelerator.siemens.cloud/locations/2654"
}
}
}
The following are the possible semantics of location when the link "location" is in the payload.
- the API client knows that the device is already onboarded (installed) in a location
- the API client could follow the link to get more information about the location of the device
If there are reasons for not using hypermedia, at least level 2 should be used.
If the HTTP verbs are the only verbs in your API, this might often lead to differences between the internal domain model and the REST model.
For example, consider a Java class that implements a printer.
public class Printer {
public void print(Document document) {
// ...
}
}
Here method print is represented by a verb. But how would you implement print method with a level 2/level 3 REST API, where you should not use other verbs than provided by HTTP?
In the REST API you would create a new PrintJob REST resource with a POST request, providing properties for the Printer resource and the document in the request body. This has the advantage that you could query all print jobs with a get request, you could delete print job resources with HTTP delete, and so forth.
Caching with ETags¶
There are many use cases where the performance of an API can be improved by using caching mechanisms. One of those is the caching based on ETags (Entity Tags). An ETag is an HTTP response header returned by an HTTP/1.1-compliant web server used to determine change in content at a given resource URL.
Here is the general workflow: A service might return an ETag in a response header. Then, when the service is called again, the ETag is passed in an If-None-Match request header. If the content changed compared with the first call, the service will return the new result. But if the content did not change, the service will return with an HTTP status code 304 (Not Modified) and an empty body.
Then the API client does not have to parse and process the result again because nothing changed.
A concrete service call could look like
curl -H "Accept: application/json" -i https://ews.siemens.com/api/devices/1
Then the service might return
HTTP/1.1 200 OK
ETag: "f88dd058fe004909615a64f01be66a7"
Content-Type: application/json;charset=UTF-8
Content-Length: 108
and the body of the response contains the device resource. Now the service is called again
curl -H "Accept: application/json" -H 'If-None-Match: "f88dd058fe004909615a64f01be66a7"'
-i https://ews.siemens.com/api/devices/1
If the content of the result that matched the ETag did not change, the service will return
HTTP/1.1 304 Not Modified
ETag: "f88dd058fe004909615a64f01be66a7"
and the body of the response will be empty.
Many REST libraries provide support for ETags, so you should consider providing the caching mechanism if it makes sense for your use case.
Additional information about ETags can be found in Hypertext Transfer Protocol (HTTP/1.1): Conditional Requests.
Optimistic Locking with ETags¶
In a multi-user environment, many REST API implementations support the approach "the last write wins" strategy. With this strategy, the latest data update overrides earlier updates. This can be an important part of a REST API, especially if you expect concurrent update requests for the same resource.
There are two models for updating data in a persistence layer:
Pessimistic locking: A user has to lock a resource before updating it. Other users cannot update the resource until the lock owner releases it.
Optimistic locking: Resources are not locked. But when updating it, the version of the resource to update has to be passed. If the version is the current version of the resource, the update will be granted, otherwise, the update will be rejected.
The usage of ETags is a common way to implement optimistic locking in REST APIs.
- The API client requests a resource from the server.
- The server generates an ETag, assigns it to the resource, and gives a 200 Response (OK) for the resource.
- Let's assume the first generated ETag is "12345".
Now a PATCH or PUT request is sent to the server with the ETag in the If-Match header.
PATCH /devices/16542 HTTP/1.1
If-Match: "12345"
{
"data": {
"type": "devices",
"id": "16542",
"attributes": {
"name": "Fire detector 143"
}
}
}
If the device resource hasn't been changed on the server, the resource will be updated and the server will generate a new ETag.
If the API client did the same call again with the old ETag, like
PATCH /devices/16542 HTTP/1.1
If-Match: "12345"
The resource will not be updated and the server would return an HTTP 412 (Precondition Failed) response, like
HTTP/1.1 412 Precondition Failed
{
"errors":[
{
"status": "412",
"title": "Precondition Failed",
"detail": "The version 12349 of the existing device doesn't match the ETag 12345"
}
]
}
Correlation IDs and tracing in distributed systems¶
Correlation IDs are identifiers that help service providers trace requests across multiple services, which is particularly valuable in distributed systems. It's also a good practice to add correlation IDs to log messages, only then the relationship between correlation ID and logs can be represented reliably. This approach can give valuable insights to developers and can be an integral part of efficient troubleshooting.
Generating correlation IDs¶
Correlation IDs can be generated by an API gateway or by initiators of a call chain. The correlation ID should be a unique identifier, it is common to use a UUID.
Example of a correlation ID added by an API gateway:
PATCH /devices/1 HTTP/1.1
X-Correlation-Id: fe8793b2-1bf0-4d29-bf10-adcf72640ec5
Propagating correlation IDs¶
The fundamental principle of correlation IDs is that the same correlation ID is forwarded to the next service call while executing the flow. This correlates the own request with the request to the next service and offers the correlation of requests and responses.
A server should, after receiving a correlation ID, make sure to include the same id when calling other services or when generating events.
Example of a correlation ID propagated in the system:
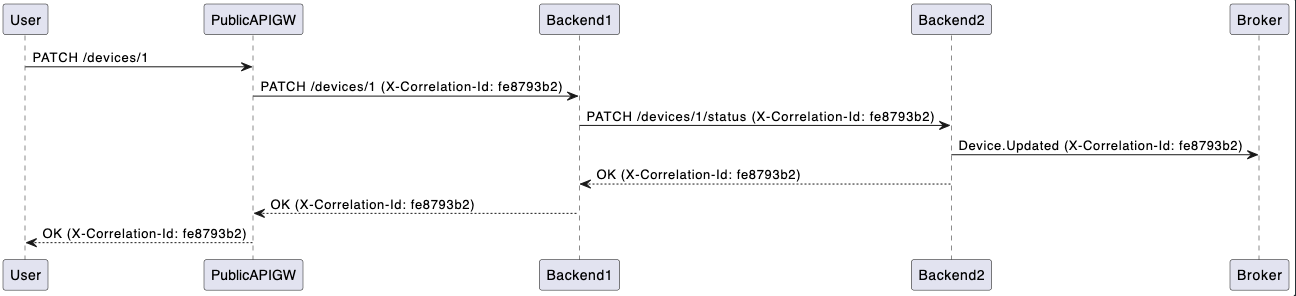
Logging of correlation IDs¶
A common way to utilize correlation IDs is to make sure that they are logged as part of a structured logging format, like JSON. Combined with centralized logging and potential indexing on the field containing the correlation ID, it provides powerful insights into the execution of a request across multiple services.
Correlation IDs in error responses¶
In case of errors during the processing of a request, the correlation ID should be part of the error response.
Dealing with binary data¶
For small binary data it is recommended to use pure REST APIs with appropriate Accept and Content-Type headers (e.g., application/octet-stream). This ensures proper handling and transfer of binary content in HTTP requests and responses.
Note
'Small' often means the default sizes for your environment. In the cloud it is often 8 MB for a request body.
Here is a simple example using curl to upload an image with an HTTPS call using the application/octet-stream content type:
curl -X POST https://api.example.com/upload \
-H "Content-Type: application/octet-stream" \
--data-binary "@path/to/image.jpg"
This sends the raw binary data of image.jpg in the request body. The server should read the request body as binary data.
For large binary data, consider using specialized approaches such as chunked uploads, streaming, or dedicated storage services. Refer to the following resources for more information:
- RFC 7231: HTTP/1.1 Semantics and Content (Section 3.1.1.5 - Content-Type)
- MDN: Guide to sending form data
- OWASP: File Upload Cheat Sheet
If you want to connect binary data with non-binary data, consider providing links to binary data in a JSON document.