
Semantic Modelling Service¶
Idea¶
The Semantic Modelling Service provides end-to-end capability to import/create, update or delete entire ontological/Semantic model.
It provides set of APIs that allow you to perform different actions on nodes and edges. It uses graph database technology to store entity relationships that are provided by users.
Access¶
Application Users can access the REST APIs using REST Client. To access Semantic service APIs, you require role/access of admin, semantic user or technical user.
For accessing this service, you need to have the respective roles listed in Data Contextualization roles and scopes.
Note
Access to Data Contextualization APIs are protected by Insights Hub authentication methods, using OAUTH credentials.
Basics¶
A graph can only two types of entities, Nodes and Edges. Data Contextualization has defined different types of nodes (knowledge points) and edges (relationships) which helps users to create a semantic model as per their domains. Data Contextualization provides some basic types of nodes and edges called global system node types. Global nodes and edges conform to Owl (Ontology web language) standard. Data Contextualization semantic model consists of namespaces, classes, schemas, class properties and schema properties, mappings between class properties and schema properties and property relations between properties of different classes.
List of global type of nodes and edges is as listed below:
Namespace: Namespace is related to a specific domain. It is highest in hierarchy in ontology/semantic model created in Data Contextualization. Semantic models are identified by namespace and ontology ID in Data Contextualization.
Class: Class denotes a business entity. There can be multiple classes associated to a single namespace. A class node consists of name and description. There cannot be 2 classes of same name within a namespace.
Property: Property/attribute is related to business class or schema. There are of two types of properties, class property and schema property. Every schema/class may have multiple properties associated with it.
Schema: Schema represents physical schema table or logical group header.
Mapping: Mapping represents an edge or relation between business property with one or more schema properties. It can be of functional mappings or key mapping type.
Key mapping is the direct mapping between the class property and one or more schema properties.
Functional mapping represents a class property as an entity that is calculated based on some arithmetic operation on one or more schema columns.
Note
In case of one-to-many key mappings, the Data Contextualization system creates an Auto INNER join between different mapped schema properties. This is done in order to find the similarity between different diverse schemas.
Propertyof: Propertyof is an edge or relation between a business class with one or more class properties. Similar relationship also exists between schema and schema properties.
PropertyRelations: PropertyRelations is an edge or relation between one class property with one or more class properties. There can be one-to-one or one-to-many property relations types.
Scope: Scope is an edge or relation between namespace and class. It is defined by default when any class is created within a namespace.
The example below explains the mapping types:
- Consider a semantic model that consists of two schemas Items and Occurrences.
- The defined columns for Items schema: itemId, itemName and force, and for Occurrences schema: itemId and position.
- The model also has a class ‘Part’ with properties partNumber, torque and itemName.
- Class property partNumber has a keyMapping with itemId column of both the schemas. Class property torque is calculated as the multiplication of force and position columns of ‘Items’ and ‘Occurrences’ schemas respectively.
- Torque property has a functional mapping with force and position columns with mapping function as product (multiplication).
Data Contextualization provides CRUD (Create, Read, Update, Delete) functionalities for entire ontologies (consisting of namespace, classes, properties, schemas, mappings, etc) corresponding to a namespace. If a user has already defined ontologies, it can be saved with ontology jobs. Users can also optionally import an existing ontological model supported with Web Ontology Language (Owl) file format extensions.
The following are APIs provided as a part of Data Contextualization semantic APIs:
- API to upload Ontology Jobs and retrieve API to get current status of Ontology Jobs. Users can create or update ontologies in JSON or Owl specified formats.
- API to retrieve status of Ontology Jobs
- API to retrieve or delete ontology based on ontology ID.
- API to infer semantic models based on selected schemas.
- API to retrieve list of ontologies in a tenant.
Features¶
The following approaches can be used to create a semantic model in Data Contextualization:
Import/Create Semantic Model: When the Data Analyst/semantic modeler has created a Semantic model, Data Contextualization provides the ability to optionally import the Semantic model as a starting point. It supports Owl or JSON file format to import Semantic model. It can be accessed by REST API with POST method to upload ontology Jobs.
Infer Semantic Model: Data Contextualization leverages extracted schema to infer correlation of data from multiple systems and provides a recommended Semantic model. User can provide a list of schemas to create Semantic model and the Infer Semantic Model API will provide inferred Semantic model. These inferred models can be retrieved based on namespace provided by user during inference of model.
This ability to infer the Semantic model reduces the investment in skillset, time and resources needed by significant amount and provides an extremely value-added starting point for the Data Analyst. It can be accessed by REST API with POST method to Infer Semantic models.Key Mapping Configuration: Data Contextualization provisions a configuration to add the type of correlation between the mapped schema properties. This configuration will enable users to retrieve commonality (INTERSECTION) as well as aggregate data (UNION) from the mapped datasets. Currently it supports two key mapping types: 1. INNER JOIN(default) to get the commonality from the mapped schemas and 2. FULL OUTER JOIN(custom) to get all the aggregated data from the mapped schemas. This configuration can be provided at two levels: 1. Ontology level and 2. Class level: The key mapping type provided at class level will override the one provided at ontology level. If user do not provide keyMappingType at ontology & class level, then INNER JOIN will be considered by default to get data from the datasets.
Limitations¶
- Data Contextualization currently supports Owl file format generated from open source tool web protégé. For details to form Owl file supported by Data Contextualization refer How to create semantic models.
- Currently, Data Contextualization semantic service supports querying with key mapping type. Semantic queries involving namespace with functional mapping is not supported.
- Data Contextualization does not allow special character such as * within attribute or class name.
- Maximum concurrent request for Data Contextualization is restricted to 30 for each tenant.
- Maximum Semantic models that can be stored in Data Contextualization is 100 for each tenant.
- Maximum size of each Semantic model can comprise of 500 classes, 2000 properties, 1000 mappings, 1000 property relations.
Example Scenario¶
An enterprise has data from PLM, ERP, CRM and HRM systems. To understand and maintain relationships between various attributes, enterprise can use Semantic Services by Data Contextualization and create a unified data model view on Data Contextualization. Various semantic queries can be built once mapping between business attributes and physical schemas is completed. Data Contextualization Semantic services will manage all the relationships, mappings and business properties for all schema properties. Finally, Semantic queries created will be associated with queryid. This queryid can directly be queried with GET query results API method. Data Contextualization will internally pick up mapping done in semantic model and provide queried results for semantic/business values.The results will depend upon the type of key mapping done in the semantic model. If the deduced key mapping type from the semantic model is INNER JOIN then the results will be the commonality between the mapped datasets and if it is FULL OUTER JOIN then the results will be aggregate data from the mapped schemas.
Let’s take an example of how configuration provided in semantic mapping would work. Consider we have 2 data sources representing inventory data of Tools used in manufacturing & information about manufacturing processes.
Data source 1 representation: Inventory Data¶
| tool_ID | quantity | Name | Desc |
|---|---|---|---|
| 1 | 100 | turret | rotating holder for tools |
| 2 | 26 | motor | lathe motor |
| 3 | 78 | belt | conveyer size 2 |
| 4 | 120 | cutter | table no4 |
| 5 | 280 | grinder | all size |
Data source 2 representation: Required tools data¶
| tool_Num | ProcessID | Process_Nam | Description | tool_desc |
|---|---|---|---|---|
| 1 | 11 | cutting | cutting of sheets | cutter in table 4 & 5 |
| 2 | 12 | milling | make precision holes to bolts | |
| 6 | 12 | milling | make precision holes to bolts | |
| 2 | 11 | cutting | cutting of sheets | table no 4 |
| 7 | 23 | welding | weld joins without bolts |
Now, let’s look at representational Semantic model based on above two data sources/schemas:
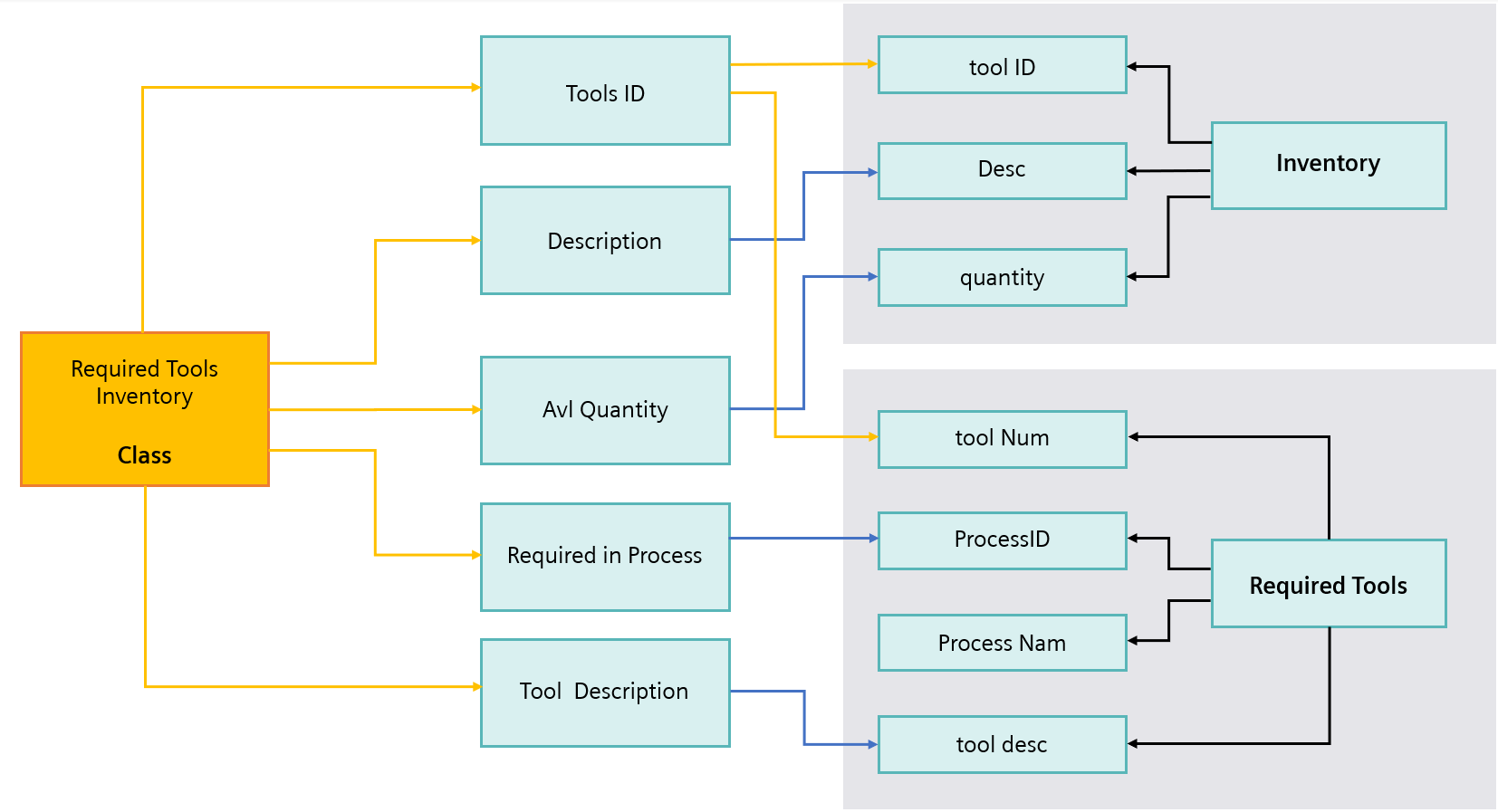
Now, once the semantic model is built on federated data sources, users can create semantic/business queries based on these models. Data Contextualization will provide you query results based on semantics & underlying data sources. You can create multiple queries on this single domain-specific semantic models (Manufacturing Tools Namespace). For example, below is the simple Query:
Select Tool ID, Description, Quantity, Required in Process, Process ID, Tool Description From Required Tools inventory (Class)
Note
The new enhancements in Data Contextualization provides further ability to provide configuration on how semantic key mappings can work. These configurations will decide how correlated data can be consumed on same semantic models & same queries.
Configuration 1 Based on commonality¶
Based on the configuration, provided query will be run on below Data representation:
| Tool ID | Description | Quantity | Required in Process | Process ID | Tool Description |
|---|---|---|---|---|---|
| 1 | rotating holder for tools | 100 | cutting | 11 | cutter in table 4 & 5 |
| 2 | lathe motor | 26 | milling | 12 | |
| 2 | lathe motor | 26 | cutting | 11 | table no 4 |
Configuration 2 Based on Union¶
Based on the configuration, provided query will be run on below Data representation:
| Tools | Description | Quantity | Required in Process | Process ID | Tool Description |
|---|---|---|---|---|---|
| 1 | rotating holder for tools | 100 | cutting | 11 | cutter in table 4 & 5 |
| 2 | lathe motor | 26 | milling | 12 | |
| milling | 12 | ||||
| 2 | lathe motor | 26 | cutting | 11 | table no 4 |
| welding | 23 | ||||
| 3 | conveyer size 2 | 78 | |||
| 4 | table no4 | 120 | |||
| 5 | all size | 280 |
This shows based that as configuration changes, in memory representation of Sematic Model also changes. As in memory data set is decided on the fly during query execution, queries using semantic model will yield different results driven by use case, based on configuration provided.